Les clés du succès d’une intelligence artificielle au service du webmarketing ?
Mise à jour — juillet 2026 : les problématiques d’attribution décrites dans cette partie se sont accentuées. Avec la généralisation du Consent Mode v2 et la modélisation des conversions, une partie des conversions rapportées par les plateformes publicitaires est désormais estimée statistiquement plutôt qu’observée. La définition rigoureuse des conversions — et leur réconciliation avec les ventes réelles, en particulier via le tracking e-commerce — est donc devenue le premier chantier de fiabilisation d’un compte avant toute automatisation.
Deuxième partie : réalité technologique derrière le discours commercial et problématique d’attribution
Dans cette partie, nous allons définir la réalité du fonctionnement de l’IA précédemment proposée par la firme de Mountain View. Nous allons voir les différents obstacles technologiques qui freinent son efficacité, et les contraintes de volume que son utilisation implique. Nous illustrerons l’étude par quelques résultats réel issu de tests menés avec certains annonceurs de l’agence.
I Fonctionnement du machine learning et des algorithmes
Le fonctionnement de l’apprentissage statistique, ou « machine learning », repose sur l’analyse d’un large volume de donnée. Plus le volume est large, plus l’efficacité du système, sur un plan prédictif, sera importante. A titre purement illustratif, rappelons ici que l’IA de Google dédié au jeu de Go, dénommée AlphaGo, qui a récemment battu le meilleur joueur mondial de Go, a utilisé un algorithme de machine learning et analysé 160 000 parties enregistrées (soit plus de 30 millions de coups différents) au préalable, pour pouvoir se mesurer à Lee Sedol.
- Importance du volume de données et taille du budget
D’après la documentation officielle de Google pour l’utilisation de l’intelligence artificielle, il est préférable de totaliser plus de 1000 impressions sur chaque annonce avant de lancer la phase d’apprentissage de l’algorithme. Voici le déroulé de la mise en place d’un process de gestion automatisé selon les consignes de Google :
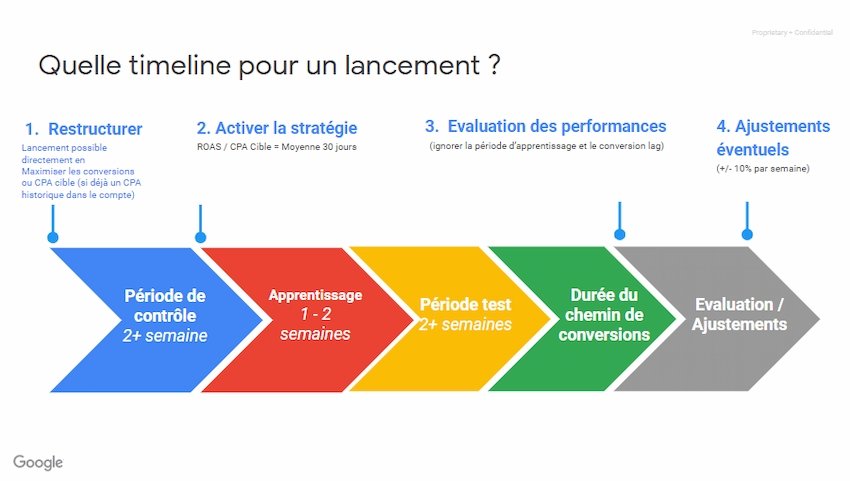
Figure 15 Déroulé de la phase d’apprentissage algorithmique pour l’automatisation d’un compte
Comme nous pouvons le constater sur cette frise chronologique, il est préférable de compter sur un total de 7 semaines (sans prendre en compte la durée de la conversion, qui peut être très impactante notamment dans les secteurs duB2Bou l’achat d’impulsion n’existe pas, ou dans des proportions très réduites). Cette période doit être respectée pour tous les annonceurs.
Rappelons que Google ne partage pas les datas entre les différents annonceurs (ou bien de façon indirecte, avec le système des Custom Intents par exemple, dont les données sont issues de la totalité de la base Google). Sur la solution Google Ads, il est obligatoire pour tous les annonceurs de laisser tourner l’algorithme sur la période indiquée pour obtenir des résultats crédibles.
Un autre élément issu du discours de Google doit être rappelé : il est conseillé pour cette phase d’apprentissage de ne pas limiter les budgets, ou bien de les plafonner à la limite la plus haute possible, pour obtenir les meilleurs résultats possibles.
Les données récoltées au cours de cette période vont permettre de maximiser l’efficacité de l’IA sur les critères suivant :
- Les analyses prédictives et le ciblage
- L’analyse comportementale
- La géolocalisation
- La définition des horaires les plus propices à la conversion
- L’attribution croisée
- L’ensemble des paramètres d’audience qui semblent définir la cible la plus adéquate (critère démographique, socio-professionnel, etc…)
Il n’existe donc pas de différence de nature entre les optimisations réalisées par l’intelligence artificielle, et celles réalisées par un gestionnaire humain. Hormis la définition de l’intention, qui peut être travaillée à part via d’autres outils des solutions Google. Cependant l’automatisation permet de réaliser des ajustements (notamment des ajustements d’enchère) beaucoup plus vite et avec un degré des réactivités très important (le système est capable, pour chaque enchère et chaque requête d’un internaute, de faire varier le montant de l’enchère via lesmart bidding, pour acquérir les clics plus susceptibles de déclencher une conversion finale).
Nous pouvons donc conclure l’analyse sur ces deux points :
- L’intelligence artificielle permet effectivement un gain de temps considérable dans la gestion d’un budget webmarketing. Il est également possible qu’elle améliore le ROAS en globalité pour un annonceur, grâce ausmart biddingautomatisé.
- Il est indispensable pour un annonceur de disposer d’un budget important pour la phase de test. Ce budget sera en partie perdue, car l’algorithme proposera des enchères très audacieuses pour pouvoir analyser les résultats sur des typologies d’internautes très différents.
L’automatisation présente des avantages indéniables, mais semble inaccessible pour la majorité des annonceurs dans les secteurs TPE et Startups. Les acteurs du webmarketing de taille importante, qui drainent un volume de clic conséquent (principalement le retail en ligne ou les grandes marques), peuvent se permettre de tester l’intelligence artificielle. La taille de leur portefeuille leur permet généralement de lancer une phase de test sur un segment de leur offre, dont le budget webmarketing est isolé pour la phase du test. Grâce à cette largeur, ils peuvent bénéficier d’un retour d’expérience sur le système tout en gardant la main sur le reste de leur portefeuille de campagnes d’acquisition en ligne.
Les annonceurs de petite taille, et les plus fragiles financièrement (ceux qui ont donc besoin d’une rentabilité réelle immédiate pour pouvoir poursuivre leurs investissements) semblent donc écarté de la course à l’automatisation. L’intelligence artificielle au service du webmarketing, telle qu’elle est proposée actuellement par Google, s’apparente à un atout de taille pour les grandes entreprises, mais totalement inadapté pour le tissu des TPE/PME.
- Un algorithme qui priorise le volume : critique de la rentabilité réelle
A cause du mode de fonctionnement réel de l’algorithme, revenons sur la rentabilité réelle générée par ce dernier. Il est intéressant de comprendre les objectifs commerciaux de Google (et d’autres grands groupes du webmarketing) qui incitent leur clientèle à l’utilisation des outils automatisés fondés sur l’intelligence artificielle.
Comme nous pouvons le constater sur la figure suivante, les « requêtes sont stables en France », ce qui indique que le volume moyen de recherche pour chaque requête existante n’est plus en croissance depuis quelques années. La grande majorité de la population disposant déjà d’un accès à internet et des outils nécessaires à la navigation (desktop ou smartphone), la demande pour chaque catégorie sémantique tend à une grande stabilité. Afin d’assurer les objectifs de croissance de la plateforme Google Ads, cette dernière doit inciter les annonceurs à augmenter le volume de clics en élargissant la couverture (donc à annoncer sur des sémantiques sur lesquelles ils n’apparaissaient pas) et à faire croître le CTR (le taux de clics sur les annonces, indice qui croit au détriment des clics sur les résultats dit « naturels » des pages de résultat de recherche.

Figure 16 Explication sur la stratégie Google pour l’accroissement du volume de clics
Il est donc pertinent d’affirmer que la priorité de l’automatisation (du côté de Google Ads) est de maximiser les revenus perçus par Google, et donc de maximiser la présence des annonces en ligne ainsi que les clics sur ces dernières.
Ce choix stratégique de la priorisation du volume implique deux problèmes pour l’annonceur :
- Peut-il encore avoir le choix sur la sémantique sur laquelle il souhaite apparaître ? Ce qui peut poser des problèmes pour l’image de marque par exemple.
- Comment prioriser le ROAS quand l’automatisation affiche clairement le volume comme objectif prioritaire ?
La réponse à ses questions est problématique. Pour la première, il apparaît que l’opacité du système et le manque d’interaction avec les équipes marketing de l’annonceur permet à Google de diffuser les annonces sur les sémantiques de son choix. Bien entendu les problèmes majeurs sont rares, et ne constituent en aucun cas la norme. Cependant, pour certains secteurs sensibles (notamment la santé et la pharmacie) ces problématiques demeurent importantes.
La seconde question appelle une réponse nuancée. L’algorithme va en effet chercher à produire du volume de clic, sur des internautes qui n’étaient pas forcément ciblés par l’annonceur auparavant. Cependant, pour permettre des stratégies d’acquisition auCPA cible,leKPIprincipal qui sera analysé par l’algorithme comme un facteur de succès est la conversion. Or, la définition de la conversion étant faite à la discrétion de l’annonceur, cela peut poser problème, principalement pour les secteurs de génération de lead — un point qu’un audit de tracking permet de sécuriser en amont.
Si l’annonceur à définit comme conversion la « vue » de la page contact du site de son entreprise, chaque clic permis par Google Ads qui aboutira à une vue de cette page sera considérée comme un succès par l’algorithme. Sans tenir compte de la rentabilité réelle (est ce que le formulaire sera correctement rempli et envoyé par l’internaute ? Le lead est il réellement qualifié par rapport à l’offre de service ou le produit de l’annonceur ?), l’intelligence artificielle va tout mettre en œuvre pour maximiser les visites de ce type d’internaute.
Sans un travail de stratégie webmarketing abouti, en amont de la phase de test de l’automatisation, le risque est donc un accroissement du volume de trafic au détriment direct de la rentabilité des campagnes webmarketing.
De plus il est important de souligner ici que pour les secteurs dont les parcours de conversion sont particulièrement longs et complexes (multi-levier et cross device), impliquant par exemple un appel téléphonique qui n’est pas tracké par la solution Google Ads, l’intelligence artificielle fonde l’optimisation de la diffusion des annonces sur des données incomplètes. Ces dernières sont loin d’être représentatives de la rentabilité réelle d’une campagne webmarketing.
Un exemple de cas particulier : le secteur des écoles de commerce
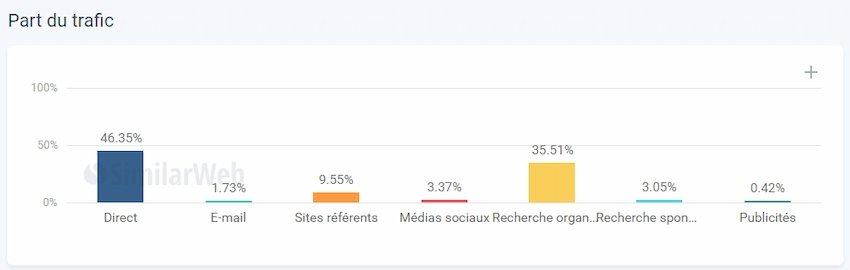
Figure 17 Données Similar Web sur les canaux d’acquisition d’un pôle de 25 écoles de commerce
Comme nous le voyons sur la figure précédente, selon une étude du trafic menée sur un segment de 25 écoles de commerces différentes, le canal direct est largement majoritaire par rapport à tous les autres, avec une moyenne de 46,35% du trafic. L’acquisition de trafic dite « directe » est la part de trafic concernant les internautes rentrant directement l’url cible dans leur navigateur, ou utilisant un bouton de favori pour accéder au site.
Nous voyons ensuite que la recherche organique (optimisée via leSEO) représente 35,5% du trafic sur les sites des écoles de commerce faisant partie de l’étude. Cependant, une analyse plus poussée de ce trafic nous oblige à nuancer cette donnée. En effet, pour presque toutes les écoles de commerce de la sélection, les requêtes à l’origine du trafic organique sont à plus de 50% des requêtes contenant le nom de l’école lui-même (c’est-à-dire des requêtes comprenant directement « Kedge » ou « Inseec » par exemple). Il faut donc comprendre que plus de la moitié du trafic organique peu être attribuée au trafic direct dans le sens ou il s’agit d’une visite due à la connaissance préalable du site par l’internaute.
Avec plus de 60% du trafic considéré comme direct sur le secteur école de commerce, analysons maintenant le fonctionnement algorithmique d’une intelligence artificielle dédiée au webmarketing. Via l’apprentissage statistique, la machine va intégrer cette importance de la notoriété pour permettre un accroissement du volume de trafic. Les outils de conseil vont donc proposer aux différents annonceurs de maximiser les budgets dédiés à la pure notoriété, comme le display avec un ciblage très large. Ce faisant, l’intelligence artificielle va essayer de produire plus de lead qualifiés issus (directement ou indirectement) de clics sur les annonces qu’elle va rendre visible pour les internautes. Pourtant cette stratégie sera contre productive, nous sommes ici dans un exemple intéressant sur l’incapacité de l’apprentissage statistique à déterminer un axe marketing permettent une réelle plu value pour l’annonceur :
- La plupart des sites d’école de commerce ne sont pas uniquement des sites d’acquisition, destinés à faire découvrir les services proposés par l’école et mettre en avant les avantages académiques de cette dernière. Ils proposent généralement des services pour les étudiants déjà inscrits, ou pour certains anciens élèves. Cette particularité explique en partie l’importance du trafic direct à destination de ces sites. Ce volume de trafic important doit être filtré par l’intelligence artificielle pour permettre un apprentissage statistiques pertinent. Or, il n’existe pas à l’heure actuelle de méthode suffisamment fiable pour exclure l’ensemble des étudiants déjà inscrits sur la base de données Google utilisée par l’automatisation.
- Le mode de fonctionnement de l’intelligence artificielle par rapport à cette catégorie sera faussé par son incompréhension du marché réel. Le marché des écoles de commerce en France étant très impacté par les résultats académiques des différentes écoles, le développement de la notoriété web d’une école n’aura qu’un impact réduit sur les inscriptions réelles (nous parlons ici des parcours classiques comme les parcours Grande Ecoles, et non des MBA et autres parcours spécialisés pour lesquels le développement de l’acquisition reste très important.) Cependant, du fait du mode de fonctionnement actuel des outils d’attribution, l’envoi d’un formulaire de demande de renseignement par un internaute sera très probablement comptabilisé comme le fruit du clic sur une annonce en display. Or il est très probable que l’internaute en question connaissait déjà l’école par d’autres biais, et que le budget investi dans cette annonce n’était donc pas réellement rentable.
Apportons cependant une nuance à l’analyse précédente : pour les internautes étrangers, qui sont moins impactés par le rôle de la presse française et des classements académiques, une campagne de développement de la notoriété web peut permettre d’apporter de bons résultats. Cependant le volume de trafic issu de pays étranger est trop faible pour permettre à une intelligence artificielle de s’optimiser via l’apprentissage statistique.
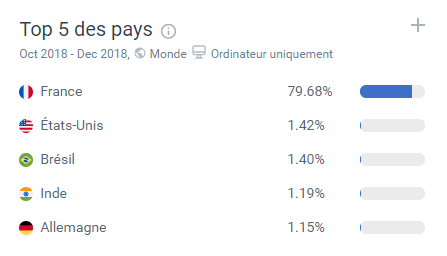
Figure 18 Trafic pas pays sur la même sélection de sites d’écoles de commerce. Source Similar Web.
II L’attribution : une guerre monopolistique handicapante pour l’IA
La problématique de l’attribution est très importante dans le cadre de l’automatisation. En effet, pour optimiser les différents leviers d’acquisition, il est nécessaire d’avoir une lecture réaliste de la valeur des différentes interactions de l’internaute au cours de son parcours de conversion. Le défaut majeur des différents systèmes d’attributions qui existent à l’heure actuelle est la difficulté à croiser des données dont les sources viennent de systèmes propriétaires différents (l’exemple classique des problèmes d’attribution entre Facebook et Google est toujours d’actualité, mais il n’est qu’un exemple parmi d’autres de cette complexité handicapante).
- Déterminer l’origine des conversions : le problème de la crédibilité
Face aux différentes solutions proposées par les GAFA concernant l’attribution, les annonceurs sont tous confrontés à la même problématique : tous les systèmes d’attribution sont des systèmes fermés qui ne communiquent pas réellement entre eux. Chaque solution de webmarketing automatisée repose en effet sur le Big Data possédé par sa compagnie. Les informations détenues par Google sont soigneusement conservées par lui, il en va de même pour les données de Facebook ou bien encore celles d’Amazon. Cette spécificité structurelle rend tous les systèmes d’attribution qui existent imprécis.
Ce problème est moins impactant lorsque les budgets webmarketing sont gérés manuellement. En effet, le ou les gestionnaires sont en contact direct avec les résultats réels de l’annonceur pour lequel ils travaillent. En cas d’incohérence entre les données résultant de l’attribution et la croissance réelle du chiffre d’affaires de l’annonceur, les gestionnaires humains vont toujours privilégier cette dernière.
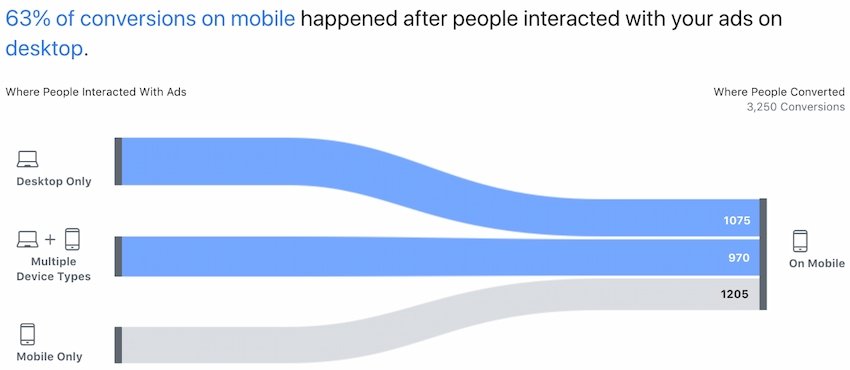
Figure 19 Illustration du système d’attribution de Facebook Ads
Dans le cadre de la mise en place d’une méthode d’apprentissage statistique par une intelligence artificielle, cette dernière doit réaliser son optimisation progressive, son « apprentissage », via lesKPIqui sont renseignés sur la structure technique du site (souvent décidé par l’agence web) : envoi d’un formulaire, achat d’un produit, visionnage d’une vidéo etc… Une intelligence artificielle Google Ads va donc s’appuyer sur son propre système d’attribution pour définir un « succès » c’est-à-dire un parcours de conversion au bout duquel l’internaute est bien à l’origine d’une conversion. C’est en fonction du nombre de succès par levier que le système va déterminer l’attribution des budgets pour favoriser la rentabilité des campagnes.
Cette vision quelque peu simpliste de l’attribution a très vite dû évoluer pour prendre en compte la complexité des canaux d’acquisition et la conversions ayant lieu suite à de nombreuses interactions entre l’internaute et le dispositif marketing mis en ligne.
Certains leviers vont récolter les premiers clics, notamment les leviers destinés à l’accroissement de la notoriété, comme le Display ou le Shopping. D’autres vont permettre de rester présent lors d’une recherche comparative de l’internaute, comme par exemple le Search. D’autres enfin vont permettre de pousser l’internaute à finaliser son parcours de conversion, il s’agit du domaine du remarketing. Les différentes plateformes ont donc mis en place un système de pondération pour permettre aux webmarketeurs de comprendre l’intérêt réel de chaque investissement, l’idée étant de pouvoir lister les plus-values de la façon suivante :
- Pour un euro investi dans l’acquisition de notoriété, quel est le montant de chiffre d’affaire généré en bout de parcours d’interaction ?
- Pour un euro investi dans les campagnes de Search, quel est le montant de CA acquis à la fin du parcours d’interaction ?
- Pour un euro investi dans le remarketing, quel est le CA généré par les conversions déclenchées par les annonces, qui n’auraient pas eu lieu sans le dispositif webmarketing.
Il est donc primordial de créer un système de pondération, puisqu’une seule conversion en bout de parcours va souvent impliquer plusieurs interactions entre l’annonceur et le dispositif webmarketing. Tant que toutes les interactions concernent le même système unique, il n’y a pas de problèmes particuliers à soulever. En effet, les gestionnaires de compte peuvent comprendre l’importance de chaque canal marketing via une analyse manuel des ROAS. De plus, de nombreux modèles d’attribution plus élaborés sont proposés par les différentes solutions de webmarketing.
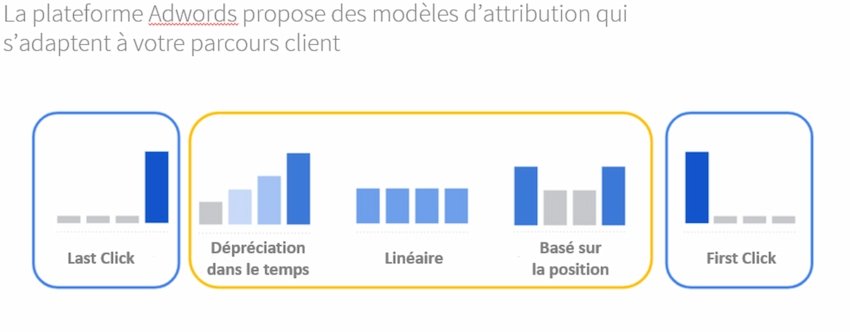
Figure 20 Exemple des modèles d’attribution proposés par Google directement dans sa plateforme Google Ads
Dans le cadre de cette étude, nous n’entrerons pas plus en détail dans les spécificités de ses différents modèles d’attribution. L’important est de rappeler qu’ils sont avant tout une simplification pour un gestionnaire humain, lui permettant de déterminer efficacement quels sont les leviers les plus performants et quels sont les budgets qui dégagent le moins deROIréel pour l’annonceur.
Il est important de rappeler que ces différents systèmes sont des outils de calcul mais qu’ils laissent le champ libre au webmarketeur pour analyser les données réelles et en tirer ses propres conclusions, ou mettre en place son propre système de pondération via une extraction des données globales.
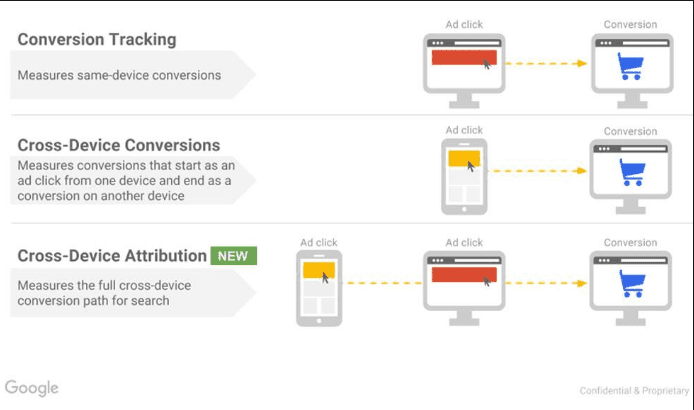
Figure 21 Ancienne présentation du nouveau système d’attribution « cross device » proposé par Google
Les différents systèmes d’attribution se sont enrichis au fil du temps, notamment pour tenir compte de la complexité des conversions multi-appareils, qui impliquent un recoupement des données de l’utilisateur sur des plateformes différentes.
Ce système d’attribution est mis en défaut dès lors que l’on doit croiser les données de plusieurs plateformes différentes. En effet, les modes de calcul ne sont pas les mêmes, chaque solution propriétaire ayant tout intérêt à attribuer des pondérations plus importantes à ses propres canaux d’acquisition. Sous couvert de considérations techniques différentes entre les diverses solutions, il est presque toujours nécessaire de retraiter les données manuellement pour avoir une vue d’ensemble réaliste du ROAS dégagé par les différents budgets investis. Certaines solutions d’attribution sont à l’étude pour palier ce problème (notamment Google Universal Attribution) mais se heurte à l’impossibilité de traiter les données issues de systèmes concurrents. Pour l’instant il n’existe pas de solution technologique fiable à ce problème.
Se pose alors le problème de la crédibilité, puisqu’il est demandé aux annonceurs, dans le cas de l’intelligence artificielle, d’autoriser l’algorithme à considérer que les données d’attribution issues de ses bases de données sur les plus fiables possibles pour déterminer la rentabilité des budgets alloués. Cette crédibilité des modèles d’attribution par plateforme n’est, à l’heure actuelle, pas à l’ordre du jour chez les professionnels du webmarketing.
Il est donc problématique de demander aux annonceurs utilisant des stratégies multi-leviers d’avoir une grande confiance dans l’automatisation des campagnes. Il apparait donc un problème structurel : les annonceurs traitant les plus gros volumes de trafic sont presque tous des annonceurs mettant en œuvre des dispositifs multi-leviers, que ce soit des marques ou des distributeurs.
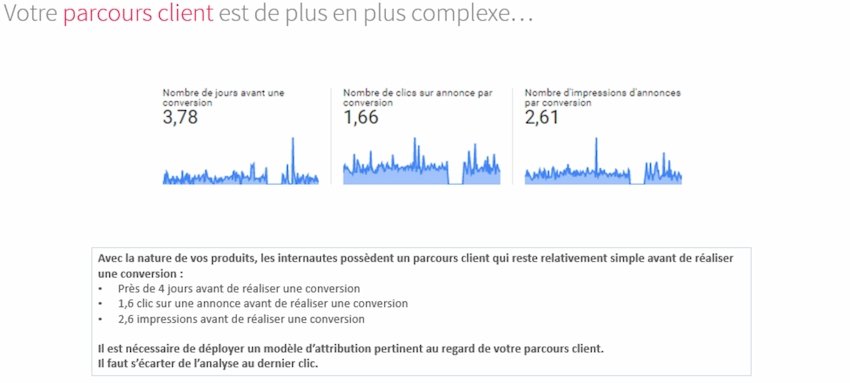
Figure 22 Une illustration du volume d’interactions par conversion pour un client de l’agence. Même pour des achats d’impulsions, la conversion immédiate suite à une seule interaction se fait de plus en plus rare
- Des annonceurs sans recours face à l’opacité technologique
A l’heure actuelle, les services marketing des entreprises avec lesquelles nous travaillons ne sont pas totalement segmentés. Même dans le cadre des grands groupes qui emploient des équipes importantes, les différents départements communiquent sur les résultats et les retours d’expérience dont ils disposent. Cela est particulièrement important pour la définition et la création des outils de communication :
- Les créations graphiques sont employées de la même façon pour la communication web que pour la communication papier.
- Les éléments de langage sont partagés entre les différents départements.
- Les données sur la cible marketing et les critères de l’audience prioritaire sont également partagés par les différents départements.
L’automatisation limitée, telle qu’elle est largement employée à l’heure actuelle pour le webmarketing, permet aux gestionnaires de mettre en place différents éléments de test & learn et de pouvoir communiquer les résultats au reste de la société. Ainsi, il est courant de constater qu’avant un évènement communicationnel important, comme un salon professionnel, certains éléments visuels et textuels sont testés par les entreprises via des méthodes d’A/B testing sur des landings pages différentes par exemple.
L’automatisation intégrale telle que celle proposée par un système comme Adwords Express (voir la partie II A) pose dès lors une difficulté, puisque le système utilise tous les éléments qu’il est possible de trouver sur le site de l’annonceur. Il est possible de retrouver les éléments publicitaires les plus efficaces a posteriori, mais il est recommandé par la plateforme de laisser le champ libre à l’intelligence artificielle pour lui permettre de trouver d’elle-même les meilleurs éléments.
De plus, il est possible que les données sur l’efficacité des différents éléments, données qui appartiennent à la plateforme de diffusion (Google, Facebook, Amazon etc…) ne soient par la suite plus communiquées directement aux annonceurs. Ces derniers se retrouveront sans recours face à l’opacité technologique imposée par une intelligence artificielle ayant emprise sur l’ensemble de leur stratégie d’acquisition. Il s’agit, la encore du discours commercial de Google, dont les cas pratiques présentés incitent à ne plus penser de stratégie d’acquisition en fonction des canaux, mais en fonction des audiences uniquement :

Figure 23 thinkwithgoogle.com/intl/fr-fr/tendances/vision/audience-et-automatisation-les-cles-de-la-personnalisation-a-grande-echelle
Face à ce type de discours, les annonceurs redoutent, à juste titre, de perdre la main sur des décisions marketing d’importance stratégique. La confiance accordée à une intelligence artificielle pour un pilotage global de la stratégie apparaît comme problématique, du fait de la faible transparence qui en résulte pour l’annonceur.
Comme nous pouvons le voir dans l’exemple ci-dessus, leKPIle plus qualitatif envisagé par Google pour définir la pertinence de la stratégie webmarketing est la « Life Time Value » d’un client, c’est-à-dire le chiffre d’affaire global généré via l’acquisition d’un client tout au long de sa vie de consommateur, et prenant en compte tous les achats générés. Cette valeur était précédemment très importante en webmarketing pour tous les secteurs fonctionnant sur l’achat récurrent. Dans le cadre du développement de l’intelligence artificielle, il est donc préconisé de prendre cette valeur comme KPI définitif, prioritaire par rapport aux autres indicateurs.